本文为 A Visual Guide to FastText Word Embeddings (amitness.com)的翻译版
如何让你的词嵌入模型能理解这几个词abandon,-s,-ed,-ing的意思是类似的呢?

1. why 要提出FastText: Word2Vec的局限
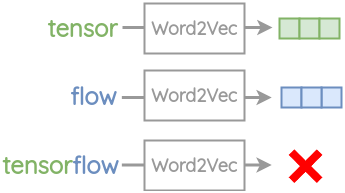
不能处理训练中未出现的词(Out of Vocabulary, OOV)
例如:tensor,flow 已在Word2Vec的词典出现过,但tensorflow未出现过→OOV error
无法处理形态相同的词(morphology),即词根相同的词
对于具有相同词根(eat)的词,eaten,eating,eats,他们之间较难同时出现,不能实现参数共享,即语义类似。因为实际中把他们都当作独一无二的词进行训练

2. FastText的提出
直觉(intuition):借鉴n-gram的思想,考虑字符级别的信息
==使用单词的内部字符信息来改善Word2Vec的语义表示==
2.1 sub-word的产生
step1 给定一个词,在词的首尾加上<>表示开始与结束

step2 设定n-gram的滑动窗口大小n=3(可以为其它大小),对该词进行滑动

step3 得到该单词一系列n-grams

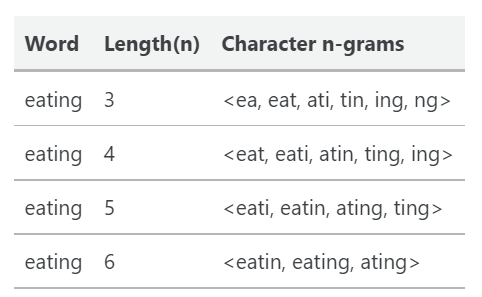
当n=,3,4,5,6时所得到的n-grams列表
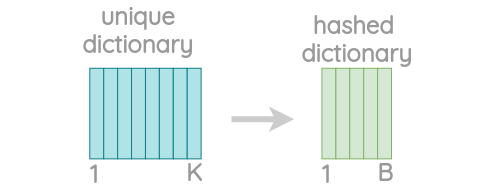
问题:这样会存在大量的唯一的n-grams
2.2 skip-gram with negative sampling:
以一个案例来理解训练过程,假设有这样一句话:eating是中心词,am与food是周围词,给定中心词预测周围词

step1 获取中心词的embedding: 将中心词与其产生的sub-words向量相加(其它合并方式会不会好一点?)获得中心词的向量$w_{center}$

step2 获取实际周围词的嵌入(没有做sub-words生成)向量$w_{am},w_{food}$与$w_{center}$

step3 获取negative samples 词:随机采样,对于一个中心词,采样5个nagative samples,比如这里其中两个词为pairs,earth,即$w_{pairs},w_{earth}$

step4 根据loss更新参数:$NEG=(w_{am},w_{food}),POS=(w_{pairs},w_{earth})$与$w_{center}$做内积运算并sigmoid,使得NEG词与center词距离越来越远,POS与center距离越来越近

3. FastText的优劣势分析
- 对于形态丰富的语言(如捷克语和德语),FastText显著提高了句法词类比任务的性能,特别是当训练语料库的规模较小时。

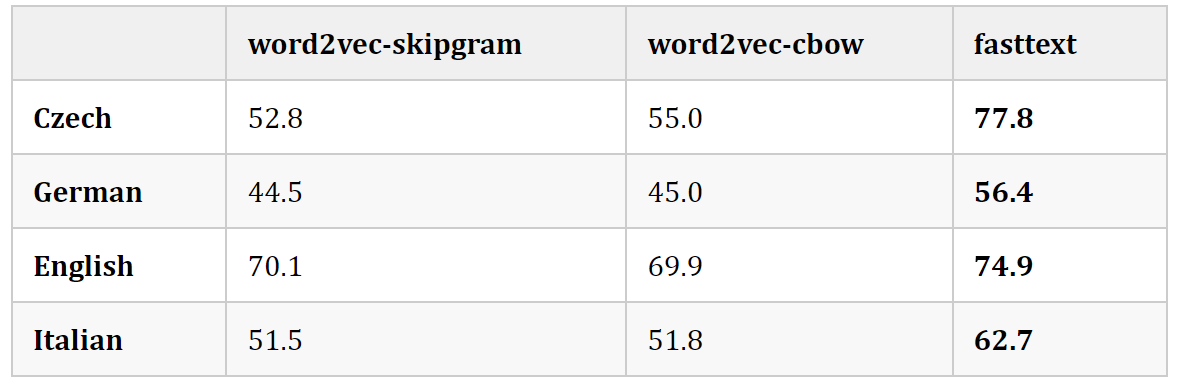
- 与Word2Vec相比,FastText降低了语义类比任务的性能,随着训练语料库规模的增加,两者之间的差异越来越小。
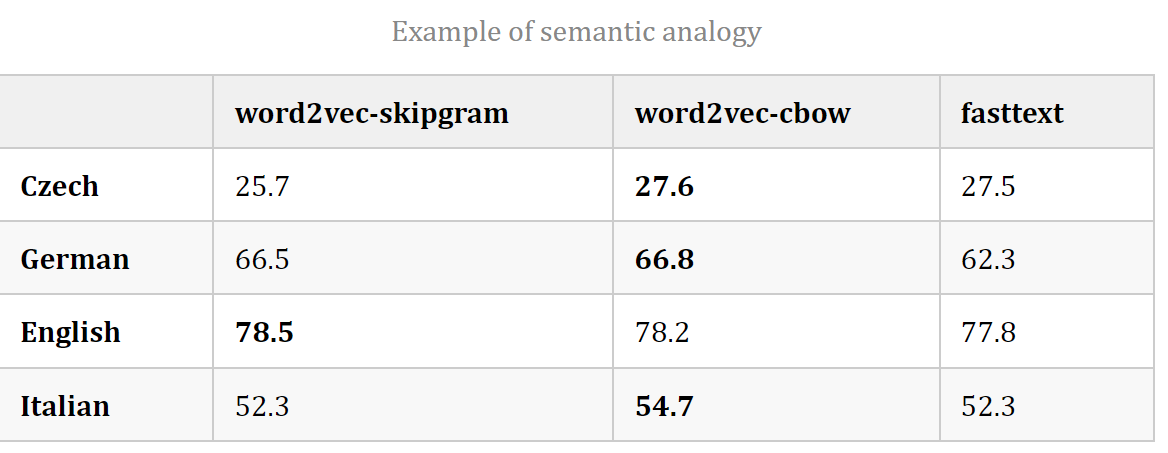
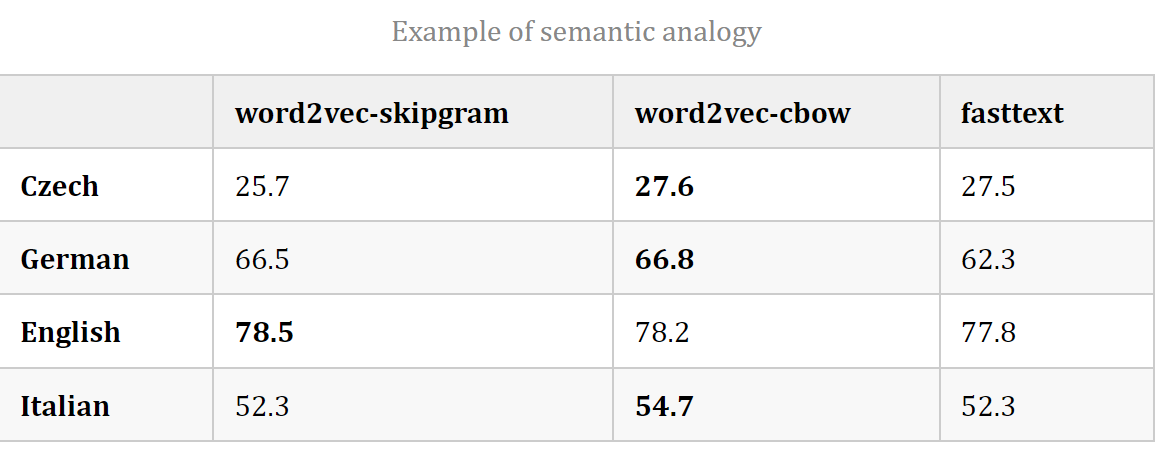
- FastText比常规的skipgram慢1.5倍,因为增加了n-grams的开销。
- 在单词相似度任务中,使用带有字符ngrams的sub-word信息比CBOW和skip-gram基线具有更好的性能。用子词求和的方法表示OOD词比用空向量表示具有更好的性能
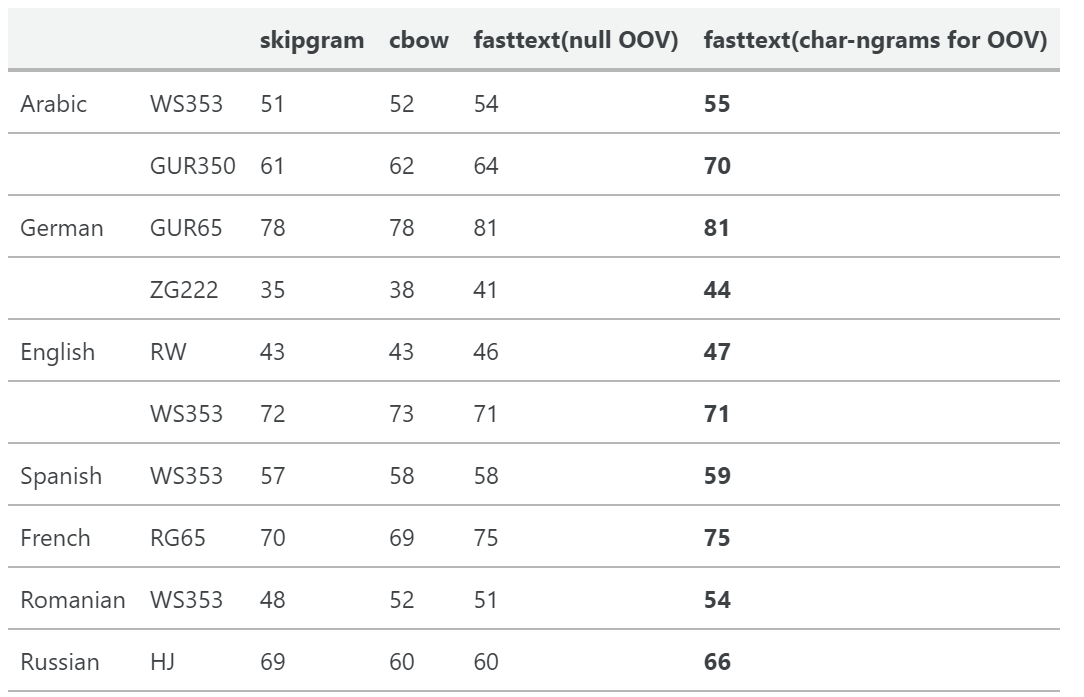
4. 思考
与字符级的命名实体识别任务思想上类似
FastText单词→字母
实体词→实体字
5.实践
训练自己的嵌入
可以使用官方CLI工具
https://fasttext.cc/docs/en/unsupervised-tutorial.html
或使用gensim的fasttext
https://radimrehurek.com/gensim/auto_examples/tutorials/run_fasttext.html
训练好的词向量
157种语言在Common Crawl和Wikipedia的预训练词向量:
https://fasttext.cc/docs/en/crawl-vectors.html,
英文词向量:
https://fasttext.cc/docs/en/english-vectors.html。
参考文献
[1] A Visual Guide to FastText Word Embeddings (amitness.com)
[2] FastText词嵌入的可视化指南 (qq.com)
[3] Bojanowski P, Grave E, Joulin A, et al. Enriching word vectors with subword information[J]. Transactions of the Association for Computational Linguistics, 2017, 5: 135-146.