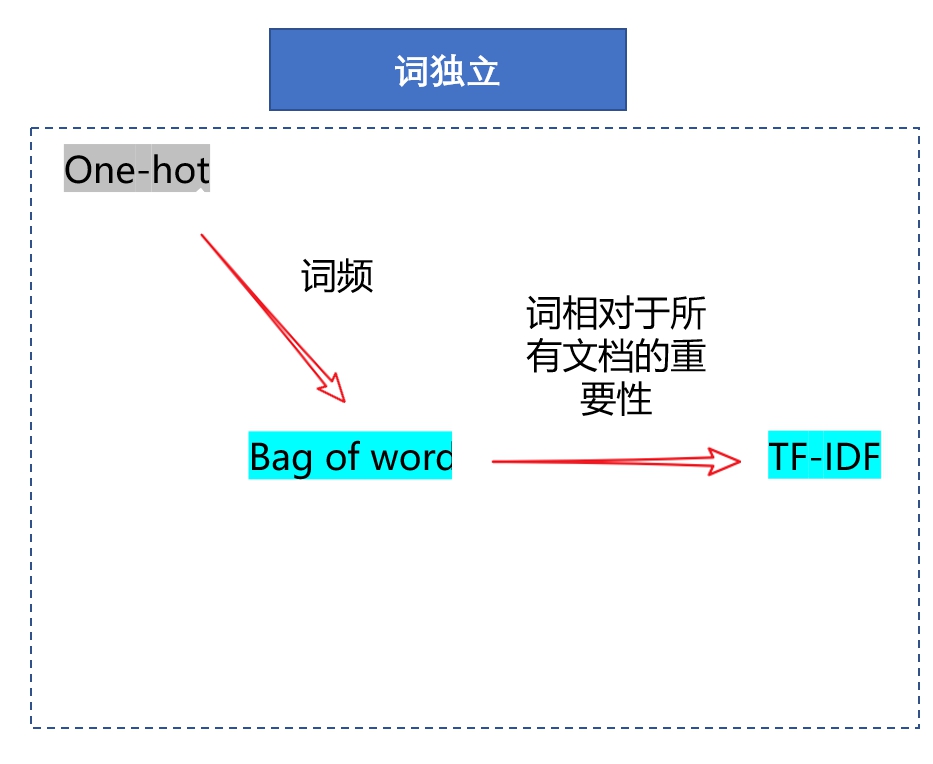
词嵌入的经典方法-独热编码(one hot),词袋模型(bag of words),词文档-逆文档频率(TF-IDF)
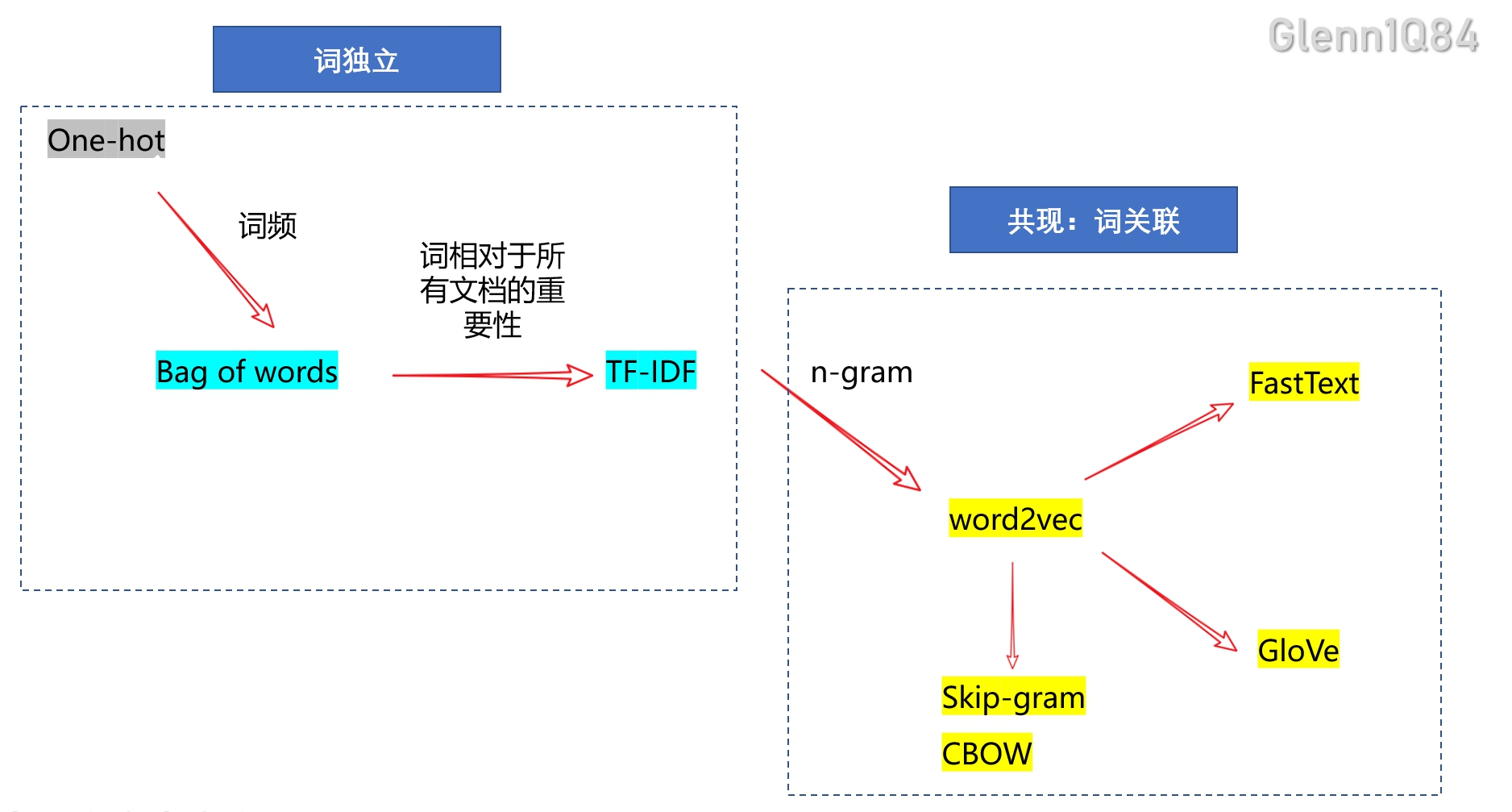
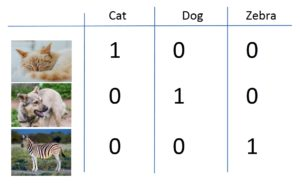
1 one-hot(独热编码)
- intuition(核心思想)
文档中每个单词的出现都是独立的,每个词都有独一无二的含义,与其它词无关。对单词编码后的向量中只有数字 0 和 1,且其中只有一个维度是 1
- 案例:
给出一句话,I ate an apple and played the piano。输出词典表示
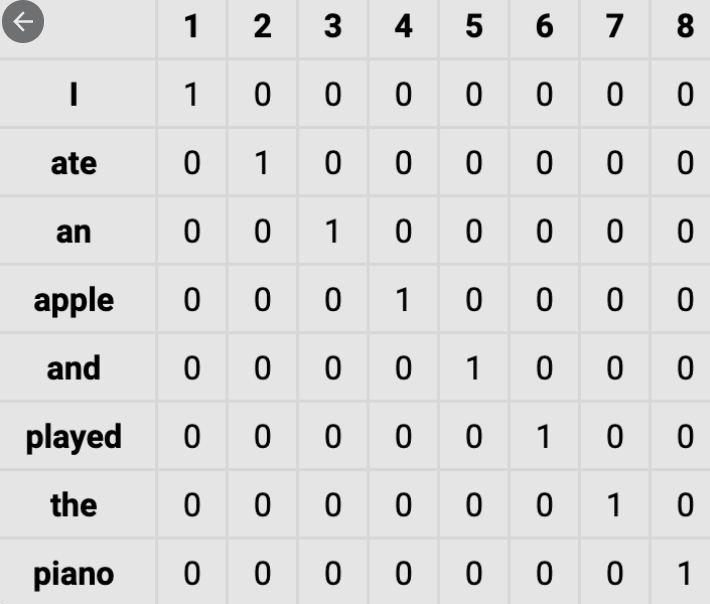
- 劣势
稀疏矩阵;高维;无法学习语义,向量间的距离无法反映语义差异,
- 应用:
输出类别标注
2.bag of words
-
intuition(核心思想):文档中每个单词的出现都是独立的,每个词都有独一无二的含义,与其它词无关。考虑单个文档中词频的重要性,忽略词序,词义,语境。
-
案例:
-
给出两个句子:
John likes to watch movies. Mary likes movies too.
John also likes to watch football games. Mary hates football.
根据上述两句话中出现的单词, 我们能构建出一个字典 (dictionary):
{“John”: 1, “likes”: 2, “to”: 3, “watch”: 4, “movies”: 5, “also”: 6, “football”: 7, “games”: 8, “Mary”: 9, “too”: 10} .
-
向量表示: 其中第i个元素表示字典中第i个单词在句子中出现的次数
[1, 2, 1, 1, 2, 1, 1, 0, 0, 1, 0]
[1, 1, 1, 1, 0, 1, 0, 1, 2, 1, 1]
-
-
优劣:
-
优势:向量表示比one-hot稠密,但依然很稀疏,考虑词频信息
-
劣势:稀疏矩阵;高维;无法学习语义,向量间的距离无法反映语义差异
-
-
应用场景:长文档(每个文档的词数多)的文档表示
中文:的、英文:is/are of ?
3. TF-IDF
- intuition(核心思想):如果某个单词在一篇文章中出现的频率(Term-Frequency,TF)高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类;用以评估一字词在所有文档中的一个文档的重要程度。字词的重要性随着它在单个文档中出现的次数成正比增加,但同时会随着它在所有文档中出现的频率成反比下降。
PS:
t-term 词,d-document 文档
$N$ 语料所包含的文档总数
$df_{t}$ 包含词t的文档数
$count(t,d)$ 词t在文档d中的出现次数
$TF_{t,d}$ 词t相对于文档d的重要程度
$IDF_t$ 词t相对于所有文档的重要程度
- 案例:
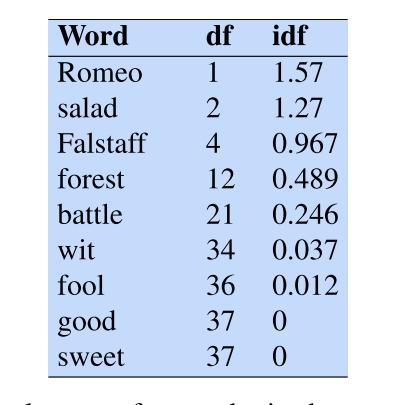
- 优劣势
-
优势:考虑了单一文档中的词频信息、==以及词在所有文档中的相对重要性==
-
劣势:没有词义
- 应用场景:关键词抽取、主题词抽取;计算文档间的相似性,文档聚类;
小结:
假设(intuition):词之间是独立的。